Anderson–Darling test
In statistics, the Anderson–Darling test, named after Theodore Wilbur Anderson (born 1918) and Donald A. Darling (born 1915), who invented it in 1952[1], is a statistical test of whether there is evidence that a given sample of data did not arise from a given probability distribution. In its basic form, the test assumes that there are no parameters to be estimated in the distribution being tested, in which case the test and its set of critical values is distribution-free. However, the test is most often used in contexts where a family of distributions is being tested, in which case the parameters of that family need to be estimated and account must be taken of this in adjusting either the test-statistic or its critical values.
When applied to testing if a normal distribution adequately describes a set of data, it is one of the most powerful statistical tools for detecting most departures from normality.[2][3]
In addition to its use as a test of fit for distributions, it can be used in parameter estimation as the basis for a form of minimum distance estimation procedure.
K-sample Anderson–Darling tests are available for testing whether several collections of observations can be modelled as coming from a single population, where the distribution function does not have to be specified.
Contents |
The single-sample test
The Anderson–Darling and Cramér–von Mises statistics belong to the class of quadratic EDF statistics (tests based on the empirical distribution function).[3] If the hypothesized distribution is F, and empirical (sample) cumulative distribution function is Fn, then the quadratic EDF statistics measure the distance between F and Fn by
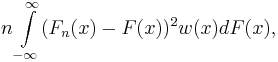
where w(x) is a weighting function. When the weighting function is w(x)=1, the statistic is the Cramér–von Mises statistic. The Anderson–Darling (1954) test[4] is based on the distance
![n \int\limits_{-\infty}^\infty \frac{(F_n(x) - F(x))^2 }
{[F(x)\; (1-F(x))]} \, dF(x),](/2012-wikipedia_en_all_nopic_01_2012/I/07df2e60687a8d9032ac43f709a05a6d.png)
which is obtained when the weight function is ![w(x)=[F(x)\; (1-F(x))]^{-1}](/2012-wikipedia_en_all_nopic_01_2012/I/34a16f923252e089978f91a32eabc308.png) . Thus, compared with the Cramér–von Mises distance, the Anderson–Darling distance places more weight on observations in the tails of the distribution.
. Thus, compared with the Cramér–von Mises distance, the Anderson–Darling distance places more weight on observations in the tails of the distribution.
Basic test statistic
The Anderson–Darling test assesses whether a sample comes from a specified distribution. It makes use of the fact that, when given a hypothesized underlying distribution and assuming the data does arise from this distribution, the data can be transformed to a uniform distribution. The transformed sample data can be then tested for uniformity with a distance test (Shapiro 1980). The formula for the test statistic  to assess if data
to assess if data  (note that the data must be put in order) comes from a distribution with cumulative distribution function (CDF)
(note that the data must be put in order) comes from a distribution with cumulative distribution function (CDF) 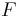 is
is
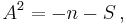
where
![S=\sum_{k=1}^n \frac{2k-1}{n}\left[\ln( F(Y_k)) %2B \ln\left(1-F(Y_{n%2B1-k})\right)\right].](/2012-wikipedia_en_all_nopic_01_2012/I/326ca06967fb47f29014d32a588bfb0d.png)
The test statistic can then be compared against the critical values of the theoretical distribution. Note that in this case no parameters are estimated in relation to the distribution function F.
Tests for families of distributions
Essentially the same test statistic can be used in the test of fit of a family of distributions, but then it must be compared against the critical values appropriate to that family of theoretical distributions and dependent also on the method used for parameter estimation.
Test for normality
In comparisons of power, Stephens[2] found 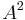 to be one of the best Empirical distribution function statistics for detecting most departures from normality. The only statistic close was the
to be one of the best Empirical distribution function statistics for detecting most departures from normality. The only statistic close was the 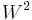 Cramér–von Mises test statistic. It may be used with small sample sizes n ≤ 25. Very large sample sizes may reject the assumption of normality with only slight imperfections, but industrial data with sample sizes of 200 and more have passed the Anderson–Darling test.
Cramér–von Mises test statistic. It may be used with small sample sizes n ≤ 25. Very large sample sizes may reject the assumption of normality with only slight imperfections, but industrial data with sample sizes of 200 and more have passed the Anderson–Darling test.
The computation differs based on what is known about the distribution:[5]
- Case 1: The mean
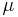 and the variance
and the variance 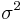 are both known.
are both known. - Case 2: The variance is known, but the mean is unknown.
- Case 3: The mean is known, but the variance is unknown.
- Case 4: Both the mean and the variance are unknown.
The n observations 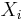 , for
, for 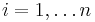 , of the variable
, of the variable 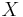 that should be tested are sorted from low to high and the notation in the following assumes that Xi represent the ordered observations. Let
that should be tested are sorted from low to high and the notation in the following assumes that Xi represent the ordered observations. Let
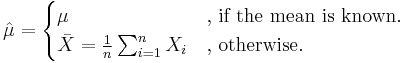

The values are standardized to create new values 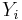 , given by
, given by
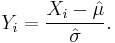
With the standard normal CDF 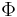 , is calculated using
, is calculated using
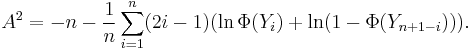
An alternative expression in which only a single observation is dealt with at each step of the summation is:
![A^2 = -n -\frac{1}{n} \sum_{i=1}^n\left[(2i-1)\ln\Phi(Y_i)%2B(2(n-i)%2B1)\ln(1-\Phi(Y_i))\right].](/2012-wikipedia_en_all_nopic_01_2012/I/4662a90ff716af0a722be5eb445b632f.png)
A modified statistic is calculated using

If 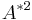 exceeds a given critical value, then the hypothesis of normality is rejected with some significance level. The critical values are given in the table below (valid for
exceeds a given critical value, then the hypothesis of normality is rejected with some significance level. The critical values are given in the table below (valid for 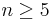 ).[2]
).[2]
Note 1: If 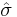 = 0 or any
= 0 or any 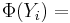 (0 or 1) then cannot be calculated and is undefined.
(0 or 1) then cannot be calculated and is undefined.
Note 2: The above adjustment formula is taken from Shorak & Wellner (1986, p239). Care is required in comparisons across different sources as often the specific adjustment formula is not stated.
Note 3: Stephens[2] notes that the test becomes better when the parameters are computed from the data, even if they are known.
| Significance | Case 1 | Case 2* | Case 3 | Case 4 |
|---|---|---|---|---|
| 15% | 1.610 | ? | ? | 0.576 |
| 10% | 1.933 | 0.908 | 1.760 | 0.656 |
| 5% | 2.492 | 1.105 | 2.323 | 0.787 |
| 2.5% | 3.070 | 1.304 | 2.904 | 0.918 |
| 1% | 3.857 | 1.573 | 3.690 | 1.092 |
(*) For the case 2, the values are for the asymptotic distribution.
Alternatively, for case 3, D'Agostino (1986, pp. 372-373)[5] gives the adjusted statistic
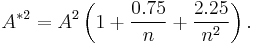
and normality is rejected if exceeds 0.631, 0.752, 0.873, 1.035, or 1.159 at 10%, 5%, 2.5%, 1%, and 0.5% significance levels, respectively; the procedure is valid for sample size at least n=8.
Tests for other distributions
Above, it was assumed that the variable was being tested for normal distribution. Any other family of distributions can be tested but the test for each family is implemented by using a different modification of the basic test statistic and this is referred to critical values specific to that family of distributions. The modifications of the statistic and tables of critical values are given by Stephens (1986)[3] for the exponential, extreme-value, Weibull, gamma, logistic, Cauchy, and von Mises distributions. Tests for the (two-parameter) log-normal distribution can be implemented by transforming the data using a logarithm and using the above test for normality. Details for the required modifications to the test statistic and for the critical values for the normal distribution and the exponential distribution have been published by Pearson & Hartley (1972, Table 54). Details for these distributions, with the addition of the Gumbel distribution, are also given by Shorak & Wellner (1986, p239). Details for the logistic distribution are given by Stephens (1979). A test for the (two parameter) Weibull distribution can be obtained by making use of the fact that the logarithm of a Weibull variate has a Gumbel distribution.
Non-parametric k-sample tests
Scholz F.W. and Stephens M.A. (1987) discuss a test, based on the Anderson-Darling measure of agreement between distributions, for whether a number of random samples with possibly different sample sizes may have arisen from the same distribution, where this distribution is unspecified.
See also
External links
References
- ^ Anderson, T. W.; Darling, D. A. (1952). "Asymptotic theory of certain "goodness-of-fit" criteria based on stochastic processes". Annals of Mathematical Statistics 23: 193–212. doi:10.1214/aoms/1177729437.
- ^ a b c d Stephens, M. A. (1974). "EDF Statistics for Goodness of Fit and Some Comparisons". Journal of the American Statistical Association 69: 730–737. doi:10.2307/2286009.
- ^ a b c M. A. Stephens (1986). "Tests Based on EDF Statistics". In D'Agostino, R.B. and Stephens, M.A.. Goodness-of-Fit Techniques. New York: Marcel Dekker. ISBN 0-8247-7487-6.
- ^ Anderson, T.W. and Darling, D.A. (1954). "A Test of Goodness-of-Fit". Journal of the American Statistical Association 49: 765–769.
- ^ a b Ralph B. D'Agostino (1986). "Tests for the Normal Distribution". In D'Agostino, R.B. and Stephens, M.A.. Goodness-of-Fit Techniques. New York: Marcel Dekker. ISBN 0-8247-7487-6.
-
- Corder, G.W., Foreman, D.I. (2009).Nonparametric Statistics for Non-Statisticians: A Step-by-Step Approach Wiley, ISBN 978-0-470-45461-9
- Pearson E.S., Hartley, H.O. (Editors) (1972) Biometrika Tables for Statisticians, Volume II. CUP. ISBN 0-521-06937-8.
- Shapiro, S.S. (1980) How to test normality and other distributional assumptions. In: The ASQC basic references in quality control: statistical techniques 3, pp. 1–78.
- Shorak, G.R., Wellner, J.A. (1986) Empirical Processes with Applications to Statistics, Wiley. ISBN 0-471-86725-X.
- Stephens, M.A. (1979) Test of fit for the logistic distribution based on the empirical distribution function, Biometrika, 66(3), 591-5.
- Scholz F.W., Stephens M.A. (1987), K-sample Anderson-Darling Tests, Journal of the American Statistical Association, 82, 918–924.